Azino777 – это игорное заведение, которое предоставляет свои услуги уже длительное время. Казино зарекомендовало себя как надежное место, где игрокам доступен широкий выбор развлечений, честная игра и быстрый вывод средств без скрытых комиссий. Именно поэтому у игроков такой интерес к этому заведению. Чтобы присоединиться к клубу, пользователь должен быть совершеннолетним и пройти регистрацию на сайте. Этот процесс занимает немного времени и может быть выполнен с помощью стационарного компьютера или мобильного устройства. Кроме того, для вывода больших сумм также потребуется верификация.

Официальный веб-сайт казино – это развлекательная платформа, через которую компания предоставляет свои услуги. Благодаря онлайн-режиму, любой пользователь может играть в игровые автоматы, карточные и настольные игры казино, независимо от места проживания. Для этого необходимо зарегистрироваться на сайте. Для осуществления крупных транзакций также требуется прохождение верификации.
Официальный веб-сайт казино имеет уникальный дизайн, который не содержит лишней анимации, что позволяет пользователям наслаждаться игровым процессом без отвлечений на различные эффекты.
Интуитивно понятное меню на портале казино помогает клиентам легко ориентироваться в получении услуг заведения.
На верхней части экрана расположены кнопки “Регистрация” и “Войти”, за которыми следует информационный блок с актуальными акциями компании. Кроме того, клуб сообщает клиентам о сумме выплат за последние 7 дней и о размере джекпота, который может быть выигран каждым пользователем.
В верхней панели представлены следующие пункты меню:
- главная;
- игровой зал;
- бонусы;
- Prime.
Основную часть страницы занимают популярные игровые автоматы, которые пользуются спросом у клиентов казино. Внизу портала располагается панель с разделами:
- главная;
- зеркало;
- бонусы;
- приложение;
- мобильная версия.
Официальный сайт казино предоставляет доступ к услугам заведения только после прохождения регистрации. Пройти регистрацию может любой совершеннолетний гражданин, без других требований со стороны компании.
Азино 777 зеркало на сегодня

Зеркало Azino777 – это копия основного сайта казино, созданная для обхода блокировок. Казино действует по лицензии из Кюрасао, но из-за запрета на азартные игры в России, официальный сайт периодически блокируется. Чтобы сохранить доступ к играм и выводу выигрышей, компания использует зеркало, которое точно повторяет основной сайт, но имеет другой адрес.
Сайт казино Azino777 и его рабочее зеркало имеют одинаковый дизайн и интерфейс. Единственное различие – веб-адрес. Регистрация возможна только на одном из них. После этого пользователь входит в систему, используя свои данные, и получает доступ ко всем услугам клуба.
Для того чтобы найти рабочее зеркало казино Azino777, можно воспользоваться следующими способами:
- Используя интернет-браузер, запрашивая информацию через поисковую строку.
- Обращаясь к форумам игроков.
- Связавшись с технической поддержкой компании, отправив соответствующее письмо по электронной почте.
- Используя социальные сети организации.
Чтобы избежать поисков рабочего зеркала, просто установите мобильное приложение на свой смартфон или планшет. Оно не подвержено блокировке со стороны надзорных органов, что позволяет пользователю получить доступ к услугам клуба в любое время и в любом месте.
Azino777 – казино

Azino777 – это онлайн казино, которое начало свою деятельность в 2011 году. Это заведение пользуется популярностью у клиентов благодаря предлагаемому честному игровому процессу и прозрачной финансовой политике. Вот еще несколько преимуществ организации:
- Для доступа к услугам казино требуется только быстрая регистрация.
- Для вывода небольших выигрышей не требуется верификация.
- Широкий выбор лицензионных игровых автоматов от известных провайдеров, настольных и карточных игр.
- Возможность играть в демо-версии игровых автоматов.
- Разнообразная бонусная программа.
- Множество вариантов вывода средств.
- Быстрые выплаты.
- Круглосуточная техническая поддержка.
Как зарегистрировать новый игровой счёт в Azino777?
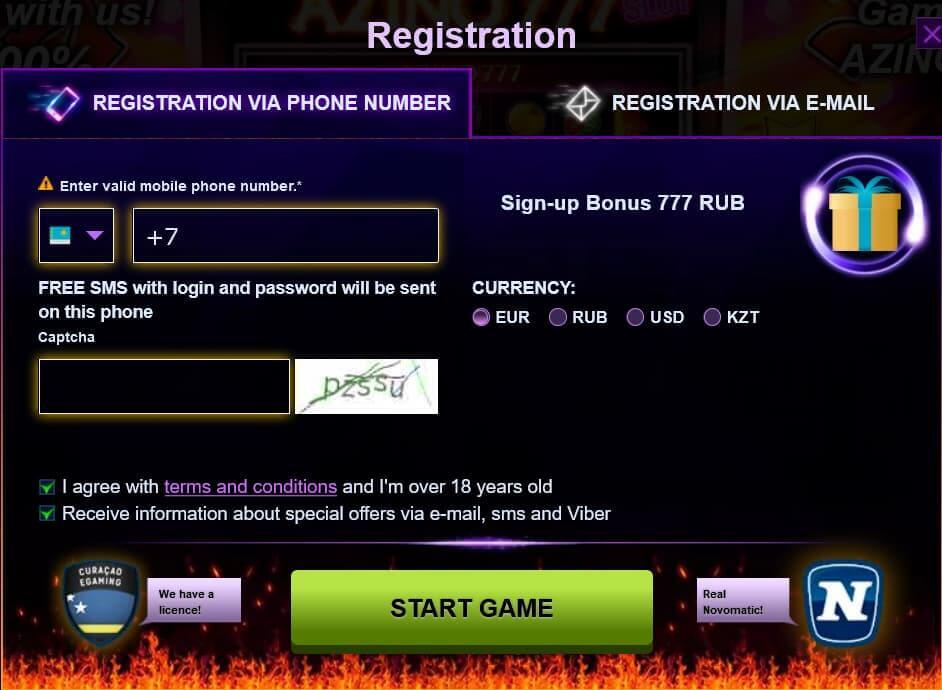
Регистрация в Azino777 занимает немного времени и выполняется двумя способами – через электронную почту или номер телефона. Чтобы зарегистрироваться, следуйте этим шагам:
- Перейдите на официальный сайт казино.
- Нажмите на соответствующую надпись в шапке портала.
- Введите номер телефона или адрес электронной почты.
- Выберите валюту для счета.
- Согласитесь с правилами и условиями компании.
- Нажмите на кнопку “Начать игру”.
После создания личного кабинета вы получите данные для входа в систему на указанный адрес электронной почты или мессенджер. Это позволит вам играть, пополнять депозит и выводить средства до 1000 долларов. Для крупных транзакций потребуется прохождение верификации.
Как войти в личный кабинет
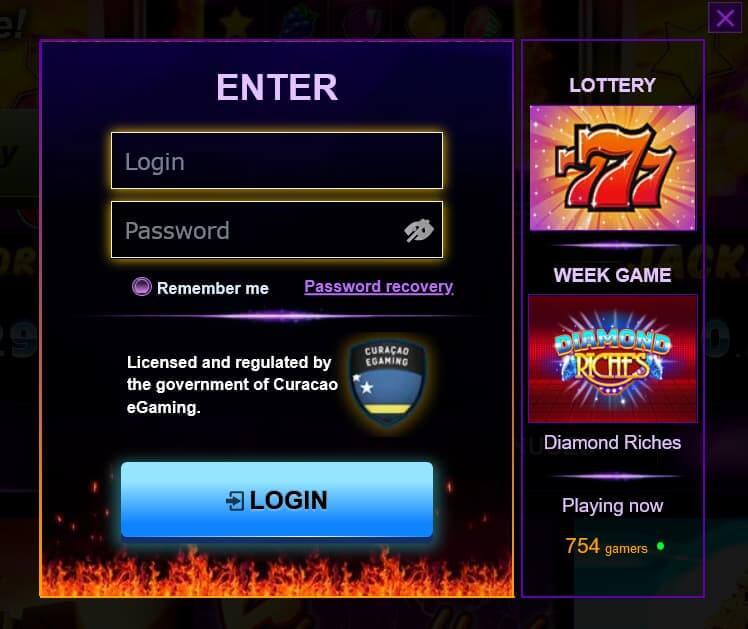
Для входа в личный кабинет в личный кабинет Azino777, необходимо выполнить следующие действия:
- открывают сайт казино;
- кликают по кнопке «Войти»;
- вводят логин и пароль;
- подтверждают, что пользователь не робот;
- нажимают кнопку «Вход».
Виды игровых автоматов в Azino 777
Azino777 предлагает широкий выбор развлечений своим пользователям. В казино представлено более 2000 видов игровых автоматов, а также рулетка, покер и другие азартные игры. В заведении доступен только лицензионный софт от проверенных провайдеров, включая следующих разработчиков:
- Spinomenal;
- Pragmatic Play;
- Quickspin;
- Ezugi;
- Bgaming.
На веб-сайте можно найти игровые автоматы с тремя или пятью барабанами. Многие из них предлагают риск-игру, бесплатные вращения и другие бонусы, которые помогают увеличить выигрыш.
Бонусы Азино777

- Казино с обширной программой бонусов для новых и постоянных клиентов.
- При регистрации новый клиент получает 777 рублей без необходимости депозита.
- Постоянные клиенты могут получить следующие поощрения:
- Подарок на день рождения до 3 000 рублей, в размере половины от последнего пополнения счета.
- Промокоды, предоставляющие доступ к различным бонусам.
- Программа лояльности для пользователей с VIP-статусом, позволяющая без ограничений выводить деньги и предоставляющая другие привилегии.
Мобильное приложение Азино 777?

Сервис Azino777 доступен не только через компьютеры и ноутбуки, но и через гаджеты, если установить специальное приложение на устройство. Эта версия подходит для всех смартфонов и планшетов, независимо от размера экрана и операционной системы. Чтобы скачать приложение, выполните следующие шаги:
- Перейдите на сайт казино с мобильного устройства.
- Откройте меню, нажав на соответствующую кнопку в верхней части экрана.
- Перейдите в раздел загрузки версии.
- Скачайте приложение и подтвердите установку.
Промокод Azino 777 на сегодня при регистрации

Промокод от Azino777 представляет собой возможность для получения дополнительного бонуса от клуба. Его нужно указать при открытии нового депозита на сайте, после чего пользователь получит денежный бонус, который сразу же зачислится на игровой счет. Промокод доступен на официальном сайте компании и также может быть найден на игровых форумах.
Azino777 – это онлайн-казино, предоставляющее услуги гражданам России, стран СНГ и других стран. Любой совершеннолетний пользователь может стать клиентом заведения после прохождения регистрации на сайте.